Ref.: Embedding
Embedding我實在不知道怎麼翻比較好,它是把高維度的資料變成低維度,並保留原始資料的特性。有了它,在像是sparse vectors這種大量input的時候,訓練model會單純一些。
**Collaborative Filtering(協同過濾)**是一種推薦系統,把看過同類型電影或廣告的人聚集在一起,並推薦可能喜歡看的其他電影或廣告。講個實際一點的例子,假設現在有史瑞克、超人特攻隊、星際大戰、記憶拼圖四部電影,我們可以依照適合年齡層排序:
再試試看能不能更多一個維度去描述電影: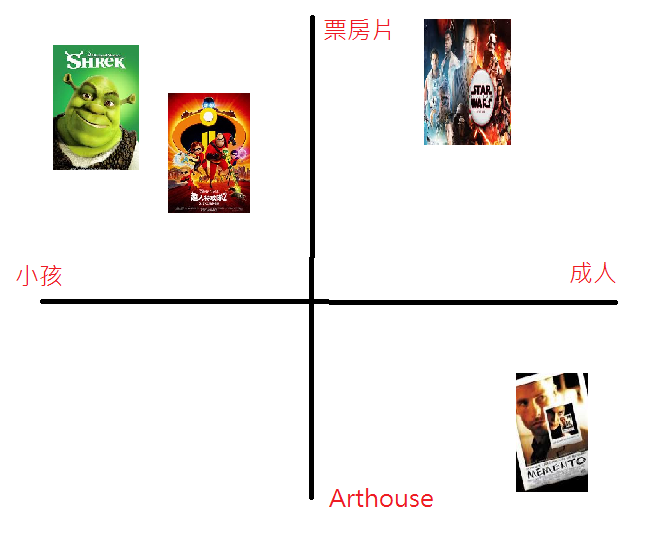
這樣一來,給每個維度不同的值,就能描繪出每個電影的差異程度,讓電影分類上更多一個feature。這邊我們設定了2個維度,所以每部電影就有兩個值(像是x, y那樣),這就是embedding space。也可以在這個空間裡面,衍生出一些額外的資訊,成為我們的latent dimension。
Categorical data(類別型資料)是把input feature一個或多個不連續的項目變成一個集合,這個集合可以像是某個user看過哪些電影、這個文件出現過哪些字之類的。
Categorical data可以用sparse tensors表達,就是其中含有一些非零的元素。下圖中,我們把給每個電影一個unique ID,每一列是一個user,並標記這個user看過哪些電影:
最後一列這位user看過movie_id = 1, movie_id = 3, movie_id = 999999這三部,sparse tensor = [1, 3, 999999]
像是這裡的推薦系統一樣,我們也可以把文字或句子用同樣的概念表達,這邊提到之前Representation講過的one-hot encoding可以處理文字,也提到了另一個方法詞袋模型bag-of-word,但無論是哪一個,input都是大量非零的向量,對訓練model不是很好。
如果input有M個字、first layer有N個資料,這樣總weight數就是M * N,可以看出來一來資料量大對training model不好、二來M * N個weights要計算也很花時間。
變成vector還有個問題,語意上雖然可以看出相似程度,但vector卻比較困難,index 1的horse vs. index 134的antelope羚羊 vs. index 30的television,會讓我們混淆到底相似程度如何。
恩!明天就要介紹到embedding layer,去解決上面的這兩個問題了。


 iThome鐵人賽
iThome鐵人賽